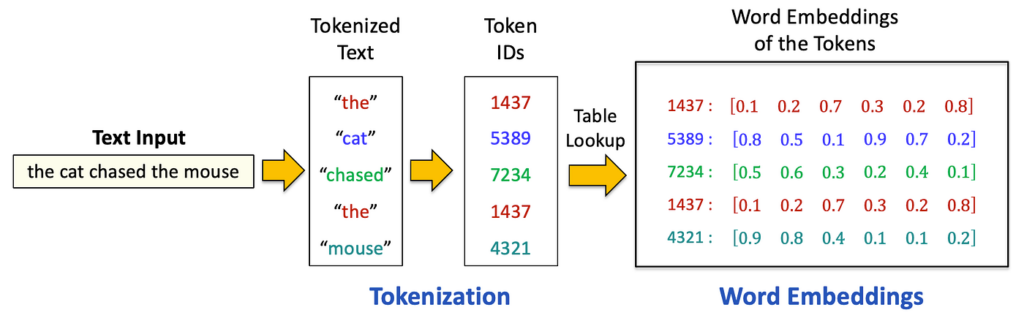
Computers cannot understand words; they only understand numbers. To bridge this gap, we use Tokenization and Embeddings.
Tokenization is the process of breaking a sentence into smaller chunks called “tokens.” A token can be a whole word, a part of a word, or even a punctuation mark. For example, the word “Lagos” might be one token, while a complex word might be split into two.
Embeddings take these tokens and turn them into lists of numbers (vectors). Think of an embedding as a map coordinates in a massive “meaning space.” In this space, the coordinates for the word “King” would be very close to the coordinates for “Queen,” but far away from the coordinates for “Bicycle.” By calculating the distance between these numbers (tokens), the AI understands how concepts relate to one another.